Подбираем ключи в А.Вордстат: самостоятельный или программный сбор и анализ статистики. Slovoeb или Key Collector
Темы подбора ключевых слов (семантического ядра), которые требуются при написании текстов для сайта и продвижения сайта в целом с помощью статей, волнует всех владельцев Интернет-ресурсов.
Достаточно разобраться в ней, чтобы начать прицельно «стрелять» по своей потенциальной аудитории наиболее мощными контент-инструментами, а все потому, что это та самая аудитория, которой данная статья интересна.
Что такое семантическое ядро и инструмент WordStat для его составления
 Нельзя утверждать, что правильно подобранные ключи потенциально несут вам успех, однако, велика сила надежды на реальное попадание в цель.
Нельзя утверждать, что правильно подобранные ключи потенциально несут вам успех, однако, велика сила надежды на реальное попадание в цель.
Если говорить иными словами, то это одна из составляющих комплексного подхода к успешному продвижению сайта в ТОП и эффективному развитию вашего ресурса. В любом случае без комплексного подхода не обойтись, если вы видите цель и твердо идете к ней.
Если коротко, то составление семантического ядра схоже с составлением схемы для программирования. В нем должны выделиться слова и словосочетания, которые называют ключевыми. Именно по ним в дальнейшем продвинется ваш проект.
Определить ключевые запросы следует предельно четко, поскольку под них в дальнейшем будут оптимизироваться страницы.
Наиболее мощным и известным способом, который дает возможность анализировать статистические данные по запросу пользователей и выдаче слов и фраз является применение инструмента Вордстат (WordStat или «статистика слов»), который предлагает Яндекс.
Это достаточно популярный путь, и его выбирает большинство рекламодателей, использующих для продвижения контекст или контекстную рекламу Я.Директ.
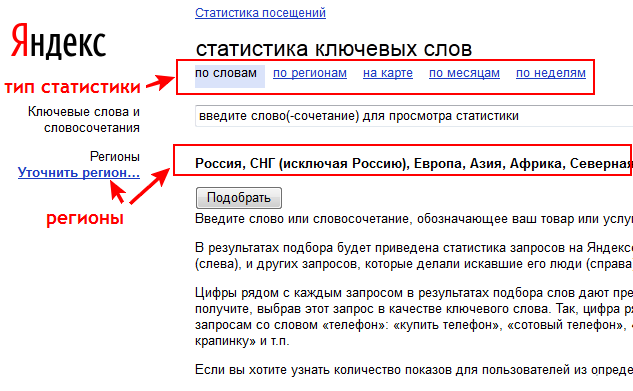
Статистика, которую выдает Вордстат, полезна для всех, т.е. для продвижения и стороннего, и собственного сайта. Работать с этим инструментом можно разными способами. Специалисты применяют программы, предназначенные для быстрого составления семантического ядра, а стандартные пользователи ведут поиск вручную.
Впрочем, пользоваться WordStat стоит в том случае, если предстоит создать целую базу ключей. Ради одной-двух фраз и слов нет смысла использовать совершенные инструменты анализа запросов.
Сервис подбора слов WordStat от Яндекс
В настоящее время Интернет буквально переполнен всевозможными статьями на тему создания семантического ядра. Пишут их, как правило, авторы, которые глубоко профессионально занимаются темой. В основном это фрилансеры разной направленности, оптимизаторы, программисты.
Они усиленно перегружают тексты специфическими фразами, которые скучны и непонятны простому пользователю. Кроме того, пути, которыми они ведут составление семантического ядра для клиента, максимально автоматизированы для экономии времени, что объективно связано с потоком задач. Если же требуется подбор ключевых слов для одного собственного сайта, как правило, не прибегают к автоматизации.
Это не только лишнее, но и может привести к обратному эффекту, т.е. потере времени, а иногда и денег. Например, прежде чем прийти к таким удобным и эффективным инструментам, как Slovoeb или Key Collector, они предварительно протестируют целый список разрекламированных инструментов для составления семантического ядра, но ни один из них не устроит.
Как правило, даже столкнувшись с толковыми и простыми программами, обыватель повертит их, поизучает и отложит. Он решит, что гораздо проще подобрать слова вручную, решив, что программа крайне сложна в освоении из-за объема функционала, а ее польза сомнительна.
Лишь отдельные единицы все-таки доходят до сути собственным умом и познают всю полезность функционала Key Collector для подбора слов и ее дочерней облегченной версии с не слишком благозвучным для России названием Slovoeb. В отличие от Slovoeb Key Collector слетает, если обновлена система, да и на другом устройстве его не откроешь. Придется начинать все сначала и связываться с разработчиком для реанимации.
Вернемся к ручному использованию инструмента Вордстат или «Подбор слов», который всем бесплатно предлагает ведущий поисковик Рунета. Несмотря на то, что предлагаются сегодня и другие аналоги, они не получили такого широкого распространения, как WordStat от Яндекс.
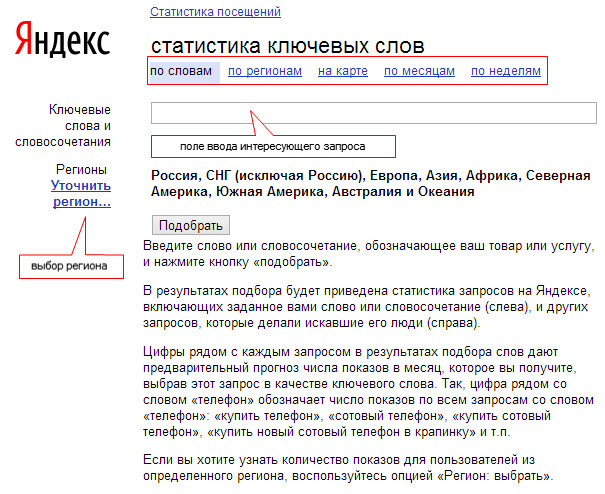
Общение с Вордстат в плане теории несложно. Практика куда скучнее и нуднее. Некоторое время назад у инструментов Яндекс поменялся дизайн, а с ним и некоторый функционал. Многие отмечают, что после обновления выросла скорость парсинга онлайн-инструмента для составления семантического ядра.
С чего начать работу с WordStat
Столкнувшись с необходимостью подобрать ключевые слова и фразы для своего сайта, многие владельцы с трудом понимают, с чего же надо начинать, а начинать надо с обдумывания того, к каким результатам хочется в конечном итоге прийти.
Начинаем с понимания тематики существующего ресурса, которая у владельца должна быть вполне сложившейся, или будущего владения. Определившись с тематикой, начинаем подбирать один-два десятка фраз или слов именно под нее. Вся эта выборка должна иметь к теме сайта непосредственное отношение, так что придется все их оценить на предмет их перспективности для продвижения вашего сайта.
Для начала, запишите все выбранные вами слова и проверьте их статистику. Все они по-разному используются при обращении к ведущему поисковику Рунета. Для оценки вам как раз и понадобится такой инструмент подбора слов, как Вордстат.

С некоторых пор WordStat стал доступен лишь после регистрации, так что потребуется пройти процедуру и получить так называемый паспорт Яндекса. У вас появится также почтовый ящик, который предоставляется бесплатно. Если регистрация уже есть, авторизуйтесь под своим логином. Пароль при необходимости можно восстановить.
Данные потребуются вам для введения в Slovoeb. Он не активизируется без этого. После авторизации введите слова и фразы по составленному вами предварительно списку. Для этого предназначена строка поиска. Она всем знакома и неизменно занимает позиции в начале страницы.
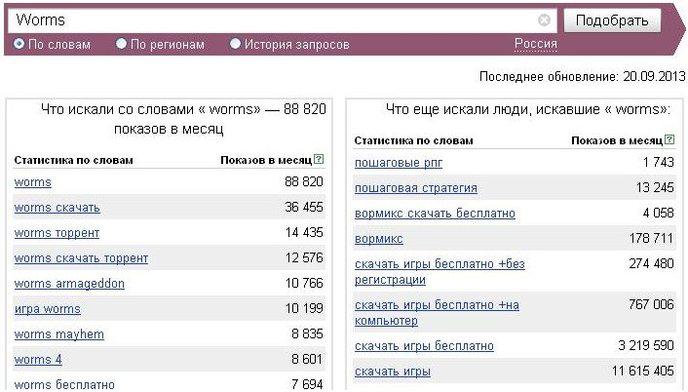
Введя слово, вы получаете результат, который виден в таблице справа. Цифры являются той самой статистикой по выбранным вами ключам, которая считается за последний календарный месяц. С учетом этого, вы можете вывести аналогичную статистику за год, но не думайте, что для каждой темы она будет просто в 12 раз больше.
Для многих запросов существует такое понятие, как сезонность. Чем выше сезон, тем больше цифра выдачи статистических данных. Для того, чтобы более точно получить годовые данные, необходимо переставив галочку в поле «История запросов».
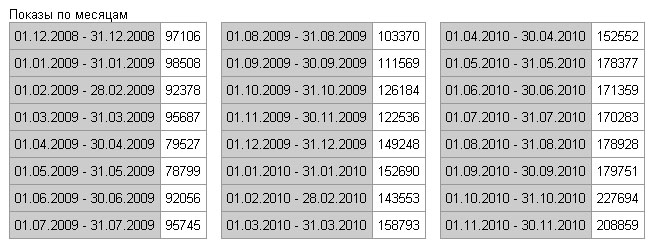
Чтобы проверить наглядно, как это работает, выбирайте что-то сильно сезонное, где летом выдача отличается в разы от зимнего периода, например, товары для дачи. Вы обнаружите, что в среднем отличие сезонной цифры от годовой иметь разницу в 6 раз.
Приступая к практическим занятиям по подбору семантического ядра, познакомьтесь с таким понятием, как дополнительные операторы, которые работают с помощью форм подбора слов. Это знаки, которые позволяют уточнить нужные вам запросы. Это оператор:
- + (плюс), позволяющий учитывать союзы и предлоги;
- - (минус), который позволяет добавить к запросу минус-слова;
- ! (восклицательный знак), который игнорирует склонения и прочие изменения слов;
- «» (кавычки) для использования только выделенных слов в неизменяемом словосочетании;
- () (круглые скобки) для учета в одном запросе нескольких разных ключевых выражений.
Как очевидно, таких операторов не слишком много, но пользуются чаще всего ! и «», так уж сложилось среди обычных пользователей. Для получения статистики больше всего помогут кавычки. Они направляют поисковик к одной выделенной фразе с учетом всех возможных словоформ.
Поставив ! перед каждым словом выбранной вами фразы, вы заставите выдать вам статистику только по текущим словоформам, без учета изменений.
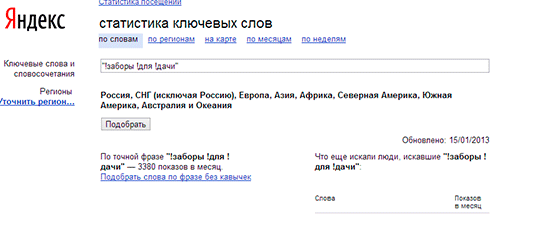
После постановки знака примерно в три раза может снизиться статистическая цифра. Попробуйте переделать запрос во множественном числе и вновь посмотреть на цифры. Они вновь изменятся, но уже по-другому.
Сборка семантического ядра сайта: что требуется учитывать
Переходим к практическим действиям. Сборка семантического ядра, которую вам предстоит проделать для получения статистических данных, складывается из ряда этапов:
1. В первую очередь занимаемся подбором ключей – слов и фраз, определением их реальной частотности в Яндекс Вордстате, как было сказано, с применением популярных операторов.
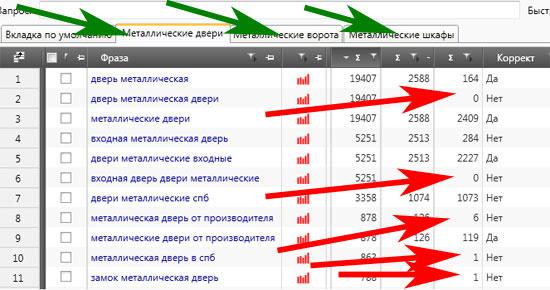
2. Выявление перспектив продвижения вашего сайта по выбранным вами запросам. Имеется в виду, что попасть в ТОП-10 будет крайне сложно, если вы выбрали для продвижения фразы, которые вместе с вами уже выбрали тысячи аналогичных сайтов. В связи с этим составляйте семантическое ядро разумно, с учетом ваших возможностей и реального, объективного конкурса в вашей сфере деятельности. Для оценки конкуренции наберите фразу в поисковой строке Яндекса и посмотрите на число ответов. При низкоконкурентном варианте их будет тысячи (менее 100 тысяч), при высококонкурентном – миллионы (более одного). Между ними расположены среднеконкурентные запросы. Еще один вариант определения относится к коммерческим ключевым запросам. Вы можете оценить фразы по MegaIndex – Мегаиндексу, или по бесплатному сервису Сеопульта. Key Collector также предоставляет данную информацию. Существуют и другие агрегаторы с подобными возможностями.
3. На третьем этапе распределите выбранные вами ключи по тем страницам ресурса, которые вы планируете продвигать, сгруппируйте их так, как считаете важным для продвижения. Это позволит вам не заказывать отдельную статью под одну ключевую фразу, а написать в целях экономии одну статью под несколько ключевых слов из Вордстата.
Проведите анализ сайтов-конкурентов, которых увидите в топе, чтобы понять, как вам выгоднее провести группировку фраз. Учиться на чужом опыте никогда не предосудительно. Если требуется продвижение информационного ресурса, просто подключите вашу человеческую логику. Она будет лучшим советником.
Кроме того, привяжите группировку к вашей теме, поскольку для некоторых выгоднее написать одну большую аналитическую статью, а для другой темы – много маленьких под один-два ключа. Иногда оптимален комбинированный вариант – одна статья большая и несколько поменьше, разъясняющих более узкие понятия, со ссылкой на основную. Практика покажет, насколько вы были точны в своих расчетах.
Разрабатывая семантическое ядро, важно зацепиться за что-то. Это означает, что вам необходимо придумать первую ключевую фразу, которую можно взять на конкурирующих сайтах. Она должна быть яркой и четкой. От нее можно начинать «плясать» в подборе ключей.
Отправной точкой могут быть сразу несколько фраз, но в любом случае при поиске стоит записывать на ходу возникающие идеи, чтобы не потерять их для получения статистики в дальнейшем, закончив в сервисе подбор слов в Вордстате от Яндекса. Просто не забудьте убедиться в ее состоятельности.
Посредством WordStat или Slovoeb для ваших статей вы сможете получить довольно объемное количество ключей из любого высокочастотного запроса. Делается это достаточно просто.
Сначала проведите подбор высокочастотных слов для вашей сферы деятельности. ВЧ – это наиболее популярные слова и фразы, которые пользователи применяют при составлении запросов в поисковике, если стремятся получить ответы на свои прямые вопросы по вашей прямой теме, с которой тесно связан продвигаемый вами ресурс.
Для того, чтобы грамотно найти такое высокочастотное словосочетание, вам надо из владельца ресурса превратиться в рядового пользователя и попытаться мыслить, как мыслит он. Формулируйте фразы так, как он будет их формулировать в поисковой строке Яндекса.
Немного отвлечемся, чтобы уточнить для тех, кто еще не сталкивался с делением запросов по частотности. Все они делятся на три категории:
- ВЧ, т.е. высокочастотные запросы,
- СЧ, т.е. среднечастотные запросы,
- НС, т.е. низкочастотные запросы.
Это деление, конечно, совершенно условно и не имеет выраженных границ. Если фраза собирает, в среднем, до 100 запросов в месяц, она низкочастотна, но при этом самая высокочастотная фраза для вашей темы должна собирать более тысячи обращений. Если же высокая частота показа в теме исчисляется сотнями тысяч и даже миллионами, то тысяча обращений будет низкочастотным показателем.
Подбор слов для семантического ядра Я.WordStat
Наберите какой-либо запрос в WordStat и проверьте, какие результаты выдаст вам статистический инструмент.
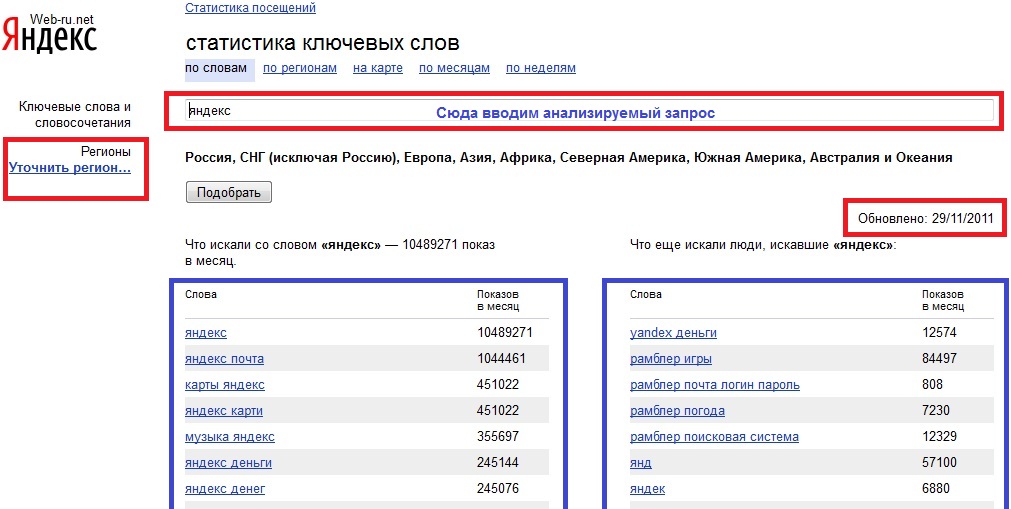
Вы получите целый многострочный, информационный список. Есть, что анализировать! Яндекс выдает этот список слов и словосочетаний на основе одной единственной введенной фразы, но при этом разводит свои находки по двум разным колонкам. Не стоит думать, что на вторую можно не обращать внимание. Если она существует, значит и она важна.
В левой выдаче WordStat собирает то, что непосредственно содержит введенные вами в строку поиска ключевые слова. В правой колонке отображается частотность запроса, который делают пользователи у популярного рунетовского поисковика. Поняв это, опять же не спешите праздновать победу. Существует такое понятие, как фейковость, т.е. частотность, показанная вам в статистике, фейковая, т.е. она может быть фиктивной. Написанные там цифры на самом деле могут оказаться чистой воды фикцией.
Проверка фиктивности данных существует. Для этого достаточно еще раз открыть WordStat в соседней вкладке вашего браузера и ввести последовательно в строку поиска фразы, собранные в левой колонке, выделив их с помощью оператора «».
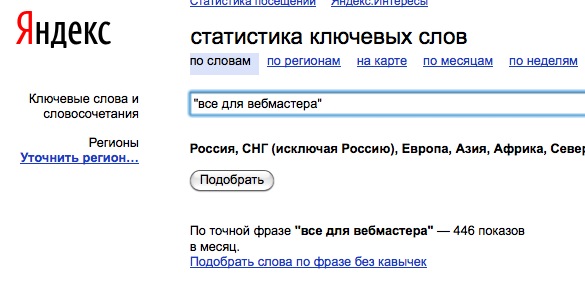
После этого вы получите уже статистику объективную, а не фейковую, или хотя бы близкую к реальному состоянию дел. Создайте для себя документ в удобном для вас Word или Exel-формате и внесите туда полученные результаты частотности для наглядности, а также для того, чтобы не потерять их.
Прочитав эти строки, многие подумают, что составлять семантическое ядро очень просто. На самом деле, это лишь теория, а научиться делать это профессионально поможет только длительная практика и учение на ошибках. Самое неприятное в этом деле – его нудность и скучность. Для того, чтобы вычислить грамотно верные результаты, придется изрядно потрудиться, проверяя десятки фраз из выданных вам в левой колонке.
Такая рутинная работа мало кому приходится по вкусу, а если знать при этом и помнить, что эта скользкая левая в выдаче WordStat имеет постраничную навигацию, станет совсем плохо. Объемы работы могут доходить до астрономических цифр. Вам потребуется, порой, вручную проанализировать до пятидесяти и более страниц Вордстата, не забывая про оператора «кавычки», из которых вы получите список в пару тысяч ключевых фраз по вашей теме!
Прочитав это, вы поймете, почему все-таки специалисты пользуются программами для автоматического анализа, но самое удивительное, что и это далеко не конец работы. Настало время вспомнить про правую колонку WordStat! В ней ваш инструмент показывает вам запросы пользователей, сделанные ими за одну поисковую сессию.
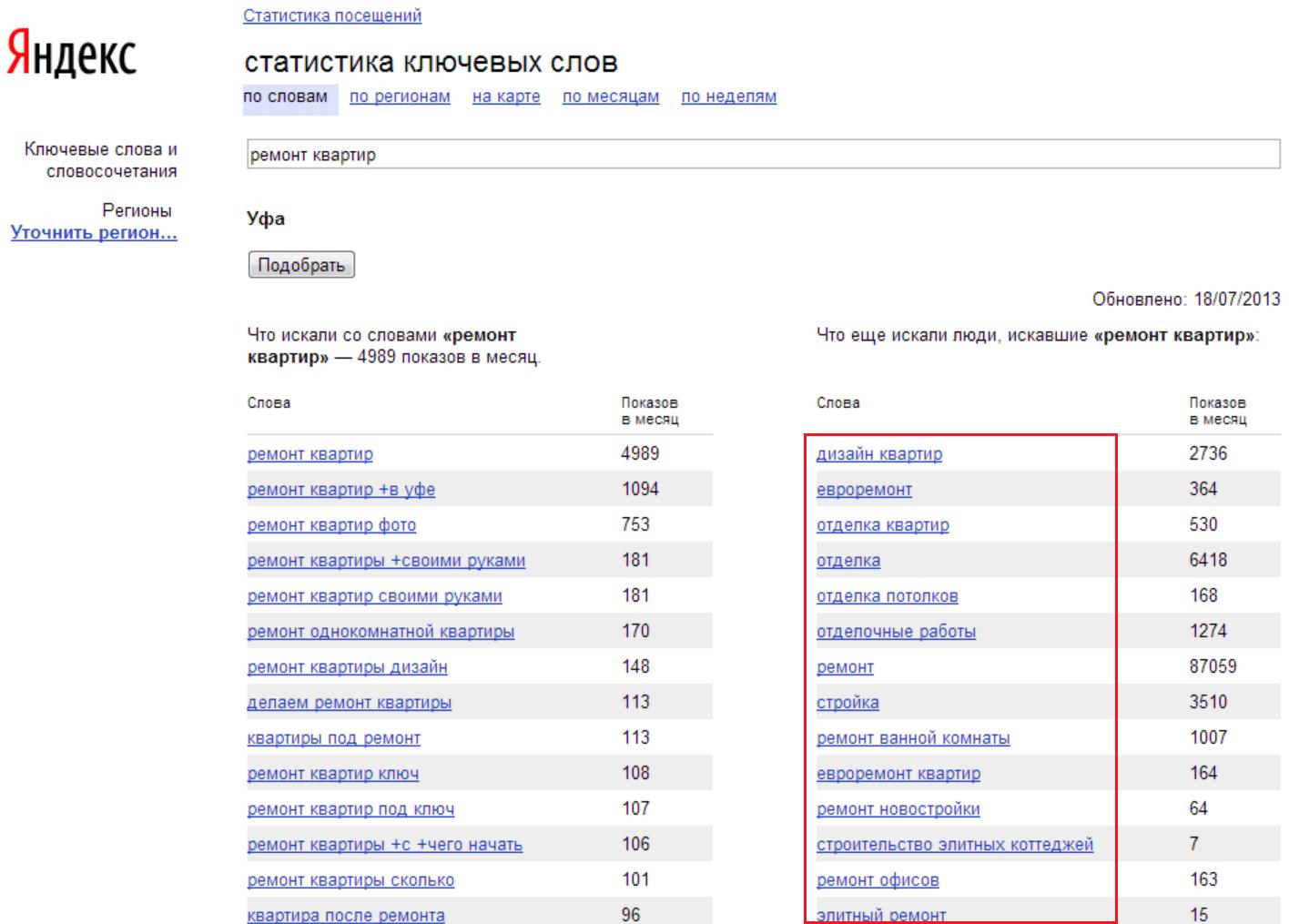
Изучив их, вы, скорее всего, вновь расширите создаваемое вами семантическое ядро. Очень часто даже специалисты не могут предсказать, в каком направлении поведет их мысль простого пользователя!
Просто посмотрите на фразы в правой колонке и оцените, насколько точное отношение они имеют к тематике продвигаемого вами ресурса. После этого перейдите на вторую открытую вкладку и пробейте их, как было описано выше. Вы опять увидите много интересного в левой колонке, и вам вновь придется проверять полученные результаты на фейк с помощью кавычек.
Просмотрите и правую колонку, поскольку в ней вы можете найти для себя что-то новое, чего еще нет в вашем семантическом ядре. Трудиться над этим анализом можно часами, открывая все новые и новые окна WordStat.
Ответственные мастера именно так и делают, чтобы не упустить ничего потенциально перспективного и не поставить в семантическое ядро заведомо никчемные пустышки. Потребуется максимальная усидчивость, чтобы добиться самых эффективных результатов. Умные мастера действуют по-другому.
Оценив те муки, которые сулит ручной подбор ключевых слов, перейдите к программе, созданной специально для того, чтобы избавить вас от рутины. Вы сразу оцените Key Collector и его упрощенный вариант Slovoeb. Еще более высокой оценки они заслужат после того, как вы проделаете ручной поиск на практике, а затем также с практической стороны оцените программ, «загнав» в нее любой ВЧ-запрос по вашей теме, случайно пришедший вам в голову.
Автомат спарсит все ваши левые колонки на многочисленных страницах и также легко сможет отсеять совершенно пустые и бесперспективные фразы. Вы получаете список реально востребованных фраз, которые не составит труда отсортировать по убыванию частотности. Программа позволяет сохранить полученные результаты в формате CSV. Их далее следует анализировать и классифицировать постатейно.
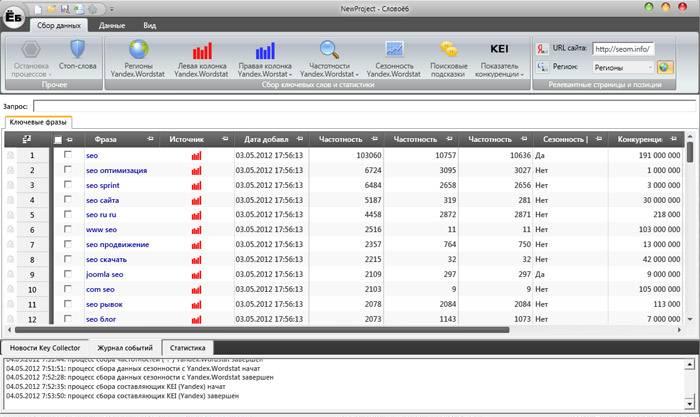
Процесс распределения ключей также поддается автоматизации. Для этого достаточно воспользоваться еще одним виртуальным сервисом. Он называется KeyAssistant и бесплатно предлагается статейной биржей Contentmonstr. Сервис позволяет распределить ключевые фразы постранично, а затем распределить страницы по разделам. На сайте биржи довольно подробно разъясняется, как действует сервис.
Автоматизация подбора слов с помощью программы Slovoeb
Не составит труда скачать Slovoeb. Он не нуждается в установке, просто распаковывается из архива и запускается традиционный файл Slovoeb.exe
В настройках найдите пункт Парсинг-Yandex Wordstat и в области настроек аккаунтов введите ваши данные – логин и пароль. Вводится пара подряд, с разделением двоеточием, не делая пробелов. Это позволит вам получить доступы к сервисам поисковика и не регистрироваться в дальнейшем для работы с Вордстат, куда пускают только авторизованных пользователей.
Аккаунты в популярном рунетовском поисковике лучше создавать пока не использованные, фейковые. Имеется в виду, что не стоит при этом подключать ваши основные аккаунты, где у вас работают такие службы, как Я.Деньги и другие.
Все дело в том, что поисковик может забанить аккаунт. Теоретически парсить без ограничений собственную выдачу напрямую Яндекс не разрешает. Для работы с XML выдачей он вводит определенные лимиты. Не стоит испытывать судьбу.
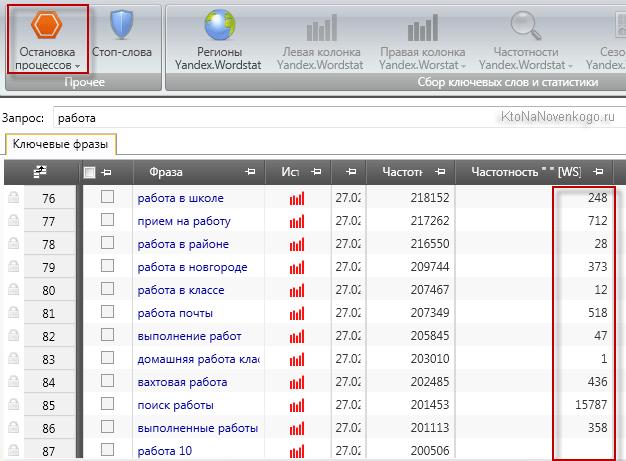
Работая с настройками, не забудьте поставить возможный максимум страниц для анализа из левой колонки сервиса Вордстат. Этот максимум равен пятидесяти. При пробивании ВЧ-запросов вам это может пригодиться, поскольку, как было сказано выше, при некоторых вариантах их выдается до пятидесяти.
Обратите внимание на то, что не все ключи, увы, можно получить с помощью Вордстат. Об этом говорит иногда проскакивающая на последней странице общая частотность, равная нескольким тысячам.
Еще одна важная настройка распложена на первой вкладке в общих. Она позволяет пользователю не слишком перегружать Яндекс, вызывая его негативную реакцию. Речь идет об увеличении диапазонов таймаутов, т.е. тех перерывов, которые автоматически случаются между подачей запросов.
После того, как вы все свои настройки сохранили, переходите к проекту. Для этого в меню выбирайте «создать или открыть» проект.
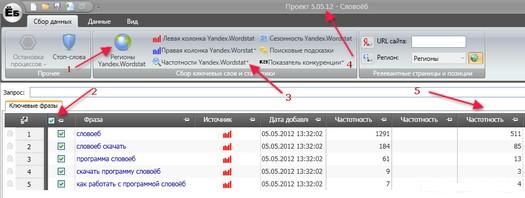
В строку введите название вашего проекта. Это может быть слово или та фраза, с которой вы стартуете. Альтернативой служит кнопка «левая колонка Y.Wordstat». Этот путь позволит вам в открывшуюся форму ввести не одну, а несколько фраз. При этом вы получаете возможность спарсить статистику по всем одновременно. Вписывайте фразы последовательно, в каждой строке. Нажав Entr, вы получаете сразу несколько списков в единой выдаче.
Последняя версия программы немного подвисает при соединении с WordStat. Речь идет только о первом соединении. Далее таких подвисаний не случается.
После старта парсинга по вашему проекту с максимальным числом страниц вы получаете две тысячи ключей, в том числе - ваше стартовое словосочетание. Для простых пользователей этого вполне достаточно. Мастера умудряются вытаскивать еще больше, но это уже явно лишнее.
Далее, важно не просто спарсить ключи с помощью удобной программы. Вам требуется понять, какие фразы ценны для вашего проекта. Вы же не будете вновь прибегать к ручному труду, чтобы составить семантическое ядро? Вам придется долго отбрасывать низкочастотные запросы.
Думаете, что вам удастся быстро вычислить то, что требуется, с помощью операторов ! и «»? Ничего подобного. В Slovoeb все предусмотрено. Достаточно выбрать в меню «Частотность Y.Wordstat» один из двух последних пунктов, который вам больше всего подходит.
Помните: проверка реальной частотности в программе пойдет куда медленнее процесса парсинга. Рекомендуется в перерыве попить кофе или чай, но не стоит заходить через браузер в Вордстат. Программа может зависнуть.
Ход процесса отражается в соответствующей колонке. Если вы фанат программы, можно, конечно, следить за бегущими цифрами, но в этом нет необходимости. Когда закончится процесс, появится серый цвет у ранее красного шестиугольника слева наверху. Вы его не пропустите.
Если у вас появится желание или необходимость, остановите процесс. Для этого можно выбрать пункт в меню. Проект сохраните, а программу закройте. Открыв ее позже, вы сможете продолжить собирать нужную вам статистику. Все предельно просто и предельно удобно.
Отсортируйте результаты в соответствии с их убыванием. Для этого необходимо традиционно нажать на заголовок столбца со статистикой фраз (в «», без них, с ! или без него).
Все наглядно, быстро, перспективно.
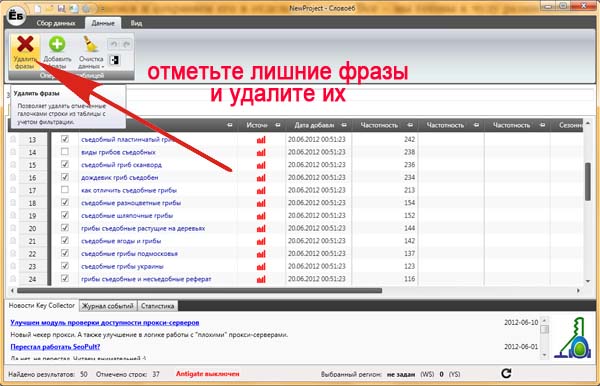
Вы можете скачать данные и сохранить их для надежности в файл формата CSV. Это можно проделать непосредственно в самой программе. Для этого нажмите на иконку в верхней части окна.
При желании сохраненный файл можно открыть в Exel. Для корректности сохранения в настройках программы в разделе «экспорт» достаточно выбрать нужный формат. Не составит труда далее откорректировать полученный файл для наглядности и удобства дальнейшей работы.
У вас получится готовый рабочий список. Из него можно брать фразы и пробивать в WordStat для получения очередных ключевых фраз. Наступает творческий процесс после совершенно рутинного, хотя, благодаря программе, не слишком утомительного.
Дополнительные статистические фукнции Slovoeb
Программа Slovoeb не ограничивается только описанным выше анализом. Она умеет отслеживать поисковые подсказки. Имеется в виду те фразы, которые при вводе ключей в строку поиска выпадают списком у ведущих поисковых машин.
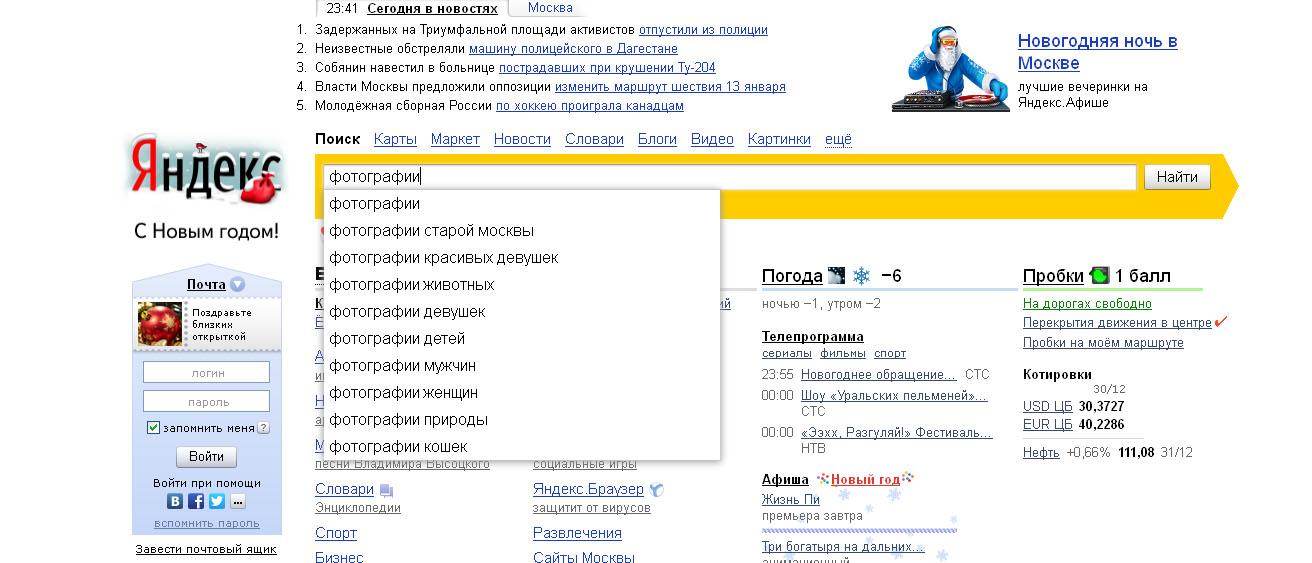
Там, порой, содержатся очень интересные варианты для получения ключевых фраз. Вы можете использовать их для дальнейшего анализа и проверки на реальную частотность.
В прежние времена пользовались специальной утилитой того же производителя. Сегодня разработчик включил данный функционал в единую программу Slovoeb.
Предусмотрена соответствующая кнопка в меню для включения функции. Она расположена на панели инструментов. Не забудьте поставить галочки на тех поисковых машинах, подсказки которых вас интересуют.
Укажите и ключевые слова для сбора по ним подсказок, как это делается и в поисковых машинах, а затем нажмите стартовую кнопку. В результате к общему списку нужных вам фраз добавятся и совершенно реальные по значимости ключи из подсказок. Далее выводите список описанным выше способом. В списке вы отличите их по особому значку, который выставляется для наглядности.
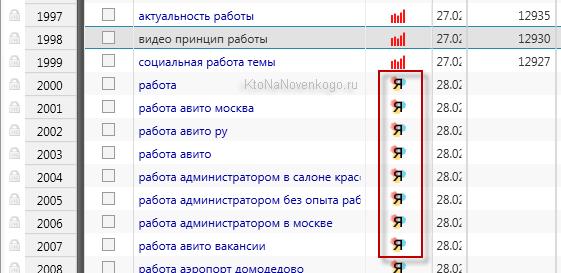
Сбор слов в правой колонке происходит аналогично. Выше уже было сказано, почему важны обе колонки в нашем процессе составления семантического ядра. Помните: чем выше конкуренция по выбранной фразе, тем сложнее вам будет с ней выбраться в топовую выдачу.
Для оценки частотности порой используется количество ответов поисковых систем по рассматриваемому запросу. Это также рассматривалось выше. Программа Slovoeb способна парсить это число для Яндекса и Гугла. Это означает, что по полученному списку вы пробьете конкурентность фраз (кнопка kei в меню Slovoeb).
Параметр данных утрирован. Если вы специалист и вам требуется на них опереться, лучше пользоваться не Slovoeb, а все-таки Key Collector. Даная версия расширенная, но платная.
В сравнении с бесплатным вариантом она куда функциональнее, но это больше подходит действительно профессиональным веб-мастерам, но даже у бесплатно версии функционал богат. Нужен ли вам более широкий? Решать только вам.
Результаты продвижения
- OOO "ПВС"
 Сайт: http://kungivsamare.ru/Сфера: Аксессуары для пикаповРегион: РоссияПродвижение:Трафик: ~7600 ч/месГрафик роста посещаемости (человек в день) по месяцам
Сайт: http://kungivsamare.ru/Сфера: Аксессуары для пикаповРегион: РоссияПродвижение:Трафик: ~7600 ч/месГрафик роста посещаемости (человек в день) по месяцам - Интернет-магазин «Аляска»
 График роста посещаемости (человек в день) по месяцам
График роста посещаемости (человек в день) по месяцам - Компания «Омега-Сити»
 Сайт: http://www.ssk-alpro.ru/Сфера: Производство и продажа торгового оборудованияРегион: МоскваПродвижение:Трафик: ~6300 ч/месГрафик роста посещаемости (человек в день) по месяцам
Сайт: http://www.ssk-alpro.ru/Сфера: Производство и продажа торгового оборудованияРегион: МоскваПродвижение:Трафик: ~6300 ч/месГрафик роста посещаемости (человек в день) по месяцам - Производственная компания «Технодрайв»
 Сайт: http://tehno-drive.ru/Сфера: Производство и продажа приводной техникиРегион: ВоронежПродвижение:Трафик: ~2900 ч/месГрафик роста посещаемости (человек в день) по месяцам
Сайт: http://tehno-drive.ru/Сфера: Производство и продажа приводной техникиРегион: ВоронежПродвижение:Трафик: ~2900 ч/месГрафик роста посещаемости (человек в день) по месяцам - Фабрика-производитель "ЭкоМассив"
 Сайт: http://eco-massive.ru/Сфера: Производство и продажа мебелиРегион: МоскваПродвижение:Трафик: ~1600 ч/месГрафик роста посещаемости (человек в день) по месяцам
Сайт: http://eco-massive.ru/Сфера: Производство и продажа мебелиРегион: МоскваПродвижение:Трафик: ~1600 ч/месГрафик роста посещаемости (человек в день) по месяцам - Туристическая компания "Тревел Бокс"
 График роста посещаемости (человек в день) по месяцам
График роста посещаемости (человек в день) по месяцам - ЗАО "Литейно-механический завод "СТЭЛЛ"
 Сайт: http://lmz-stell.ruСфера: Производсто деталей машин и оборудованияРегион: РоссияПродвижение:Трафик: ~11000 ч/месГрафик роста посещаемости (человек в день) по месяцам
Сайт: http://lmz-stell.ruСфера: Производсто деталей машин и оборудованияРегион: РоссияПродвижение:Трафик: ~11000 ч/месГрафик роста посещаемости (человек в день) по месяцам - Компания "Bluestone and Millmark Moscow"
 График роста посещаемости (человек в день) по месяцам
График роста посещаемости (человек в день) по месяцам

